Workplan status from 08/06/05
The structure of the workplan is grouped into the different types of testing activities. It also follows the phases given by the the available farm size at a give time. The testing activities are the following:
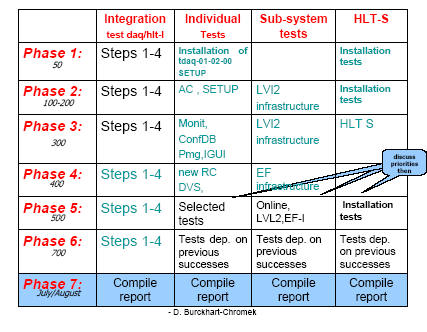
Schedule Overview:
The table for the global schedule indicates the main testing activities per testing phase. Point 1 as listed above should always be executed at the beginning of a new phase and these verification tests are not specifically listed in the table. Emphasis on the integration testing is put to the second part of the testing period. In the early phases, component testing and LVL2 tests together with the HLT-S installation tests will have priority. The availability of the testers has been taken into account as far as it is known. Phase 1 is a pre-phase when the system(s) will be installed but can be used as soon as this step is finished successfully. During or after phase 4, the priority for the last 2 phases will be set. Tests which have run successfully up to then and could give additional information about the behaviour of the system on an even larger scale will get priority. Integration tests should be run if they had been successful up to this point.
The general schema for each phase is described here, but we need to be flexible and and details will depend on the actual situation :
Involved testers:

Detailed workplan :
System integration tests and sub-system tests
Level2 tests this is a pointer to word document and not listed inline!Controls
Monitoring
Configuration database tests with oracle
CDI tests
Sub-system and system integration tests
The HLT/DAQ integration tests should follow a series of steps before combining them to the complete system to verify the basic system functionality for each phase. Then the specific sub-system and integration steps, the component tests and HLT-S tests can follow. Details of these steps are set out below:
1. Step: Online Software System : Doris + Mihai in phase
1,2,3; + someone for phases 4,5,6
- Verify the integrated functionality for startup/shutdown and state transitions. estimated time: 1 day for small partitions, shared; 2-3 for larger farms.
- Verify that the performance is in the expected range
- performance: run same partitions in automatic test mode to gain statistics; early LST phases 1 night; later phases 2 -3 nigh
run 2 level partition for the phases 1,2, and for the following phases 3 level partitions with 50 local controllers per segment, one IS server per sub-farm controller , 1 rdb server per sub-farm controller
Steps for the online:
1.)online:
topology of control tree with rc_empty_controller:
1 Root controller
n global controllers ( n to be specified)
m sub-farm controllers per global controller ( m to be specified)
p controllers per sub-farm ( p to be specified)
option of one IS server per sub-farm
option of one rdb-server per sub-farm
2) online + ExampleApplication to include an additional application per local controller:
topology of control tree with rc_empty_controller for root and intermediate controllers and the localcontroller for the leafs:
1 Root controller
n global contollers ( n to be specified)
m sub-farm controllers per global controller ( m to be specified)
p controllers per sub-farm ( p to be specified)
1 ExampleApplication per leaf controller node
option of one IS server per sub-farm
option of one rdb-server per sub-farm
3) same as 2) but ExampleApplication replaced by test_app
4) online + is_test_source to introduce IS traffic:
topology of control tree with rc_empty_controllerfor root and intermediate controllers and the localcontroller for the leafs:
1 Root controller
n global contollers ( n to be specified)
m sub-farm controllers per global controller ( m to be specified)
p controllers per sub-farm ( p to be specified)
1 is_test_source per leaf controller node, communicating with its respective sub-farm IS server
of one IS server per sub-farm
one rdb-server per sub-farm and one is_test_receiver connecting to the corresponding IS server.
Note:
is_test_source should have the followin parameters set: -p <partition-name> -n <server-name> -N 5 -S <name_suffix> -s M
and the default value for the other parameters
<name_suffix> is a string which has to be unique per is_test_source in the db
It should be set to start at start of run and to stop at stop of run
is_test_receiver -p <partition-name> -n <server-name> -u 10000
It should be set to start at start of run and to stop at stop of run
2. Step: ROS + DC: Sonja (Gokhan) for ROS, Per
for LVL2, Kostas for DC
a. ONLSW + LVL2 ROI Collection (L2SVs + L2PUs + ROSs)
description of partitions to run: (to be prepared)
estimated time for verification:
estimated time for sub-system tests:
• Test scalability aspect of High Level trigger LVL2 part of the dataflow without
algorithms. Components involved: as in step 1 + ROI Collection + O(200 ROSs, 800
LPUs, 10 L2SVs)
• Study of control aspects, robustness and stability on a large scale
• Take measurements for state transitions for varying number of sub-farms and
number of nodes per sub-farm as a test for farm control
• Inter-operability of components, use of IS and MRS while ROSes use dummy data
Use of UDP and use TCP, possibly also mixed (UDP ROS-L2PU only?) DC networks should be configured and tested.
• Study 2tier and 3tier hierarchies; vary number of sub-farms and number of applications per sub-farm
• Verify functionality for up to 8 L2PU applications per node (few algorithms run multi-threaded; multi-processor nodes)
• Don’t aim to measure performance or scalability of the DF system
• Keep data rates on DC network VERY low (high burn time) not to spoil the measurements
ROS: functionality: shared mode 1/2 day; no performance tests
LVL2: functionality:
description of partitions to run: (to be prepared)
b. ONLSW + LVL2 ROI Collection + Event Builder
description of partitions to run: (to be prepared)
estimated time for verification:
estimated time for sub-system tests:
• Components involved: as in step 2 a) + Event Builder (DFM, SFIs, ROSs)
-------------------------------------------------------------------
LST2005: Work Plan for the EventBuilding DataCollection part
-------------------------------------------------------------------
Aim:
----
Test scalability aspect of the EventBuilding part of the dataflow.
General:
--------
* Study of control aspects, robustness and stability on a full scale of
the ATLAS EventBuilder
* Take measurements for state transitions for varying sizes of the
EventBuilder as a test for RunControl
* Use of UDP and use of TCP
* Don't aim to measure performance or scalability of the EventBuilder;
i.e. very low data rates, and only a few dummy events built
Details:
--------
1) In the first phases of the Large Scale Tests, we want to run with a
partition having an EB segment with: one DFM and a few SFI's plus a
ROS segment with a few ROS's (ROS-to-SFI ratio around 3:2;
e.g., 15 ROS's and 10 SFI's). This is to prepare, test and
understand the test procedures defined in step 2) and 3) below.
2) When we have around 300 machines in the LST05, we'd like to use a
full scale version of the EB and ROS segments above:
still have one DFM, but now have ~150 ROS's and ~100 SFI's, as
foreseen for the final ATLAS DAQ system.
Also a few intermediate steps will be measured with 1/4; 1/2; and
3/4 of the full scale system.
3) Integrate with ONLSW + LVL2 ROI Collection + Event Builder tests
[i.e., step 2b) of LST workplan]:
Go back to a smaller EB segment, always with one DFM and
ROS-to-SFI machines in the ratio of 3:2 (e.g., 12 ROS's, 8 SFI's) and
allocate the available PCs to the LVL2 subfarms for testing.
4) Integration: ONLSW + L2 ROI Collection + Event Builder + EF:
[i.e., step 4) of LST workplan]:
As step 3) above, but EF subfarms added. SFIs need to connect to EFDs.
Need to add a few (max 5) SFOs in a SFO segment.
5) If at the end of the tests, as we approach the 19th of July, we have
done all the tests we want with the Online, LVL2 and EF systems, then
we could check an EB and ROS segment with twice the size of the full
ATLAS configuration: 1 DFM, 300 ROS's and 200 SFI's just to see if we
hit a wall there.
This should not have the highest priority in the overall planning,
nevertheless, if there is some time available this would be still a
useful test.
3. Step 3: ONLSW + EF (Serge and Andrea from phase 3 on, in phase 1,2 Doris)
description of partitions to run: (to be prepared)
estimated time for verification:
estimated time for sub-system tests:
• Verify robustness of the EF control and operational monitoring
• Verify that the performance is in the expected range
• Study load balancing on PTs
• Study EF communication for SFI, EFD, SFO
• Take measurements for state transitions for varying number of sub-farms and
number of nodes per sub-farm as a test for farm control1) Tests of TDAQ framework from the side of Event Filter components (EFD/PT):
WestGrid tests showed that the communication between EFD/PT or with other components of TDAQ may be an additional source of problems. Thus we would like to test (with only PTDummy, NO Athena):
- stability of FSM transitions
- EFD-PT, EFD/PT--IS/LC/IPC communications
- PT/EFD timeouts and their relations/influence
to TDAQ timeouts
- robustness of TDAQ system in case of problems
on EFD/PT side (killing PTs/EFDs, "Ignore/Restart"
flags for EFDs/PTs)
- influence of network/local_disk installations
on performance (RDB/OKS/IPC_INIT_REF as file/jacorb)
- check/unify error/logging output from EFD/PTsQ2: some scalability problems appeared during the WestGrid large
scale tests.
Q3: Andrea, Serge, Sander, Haimo
Q4: yes, Q5: yes
Q6: can run shared. exclusive access needed only in case of problems
Q7: as many nodes as possible
Q8: no
2) separate issue is comparison of performances of EF farms of different topologies (also only
PTDummy, NO Athena):
- find out optimal size of SubFarm (e.g. 10x60 or
20x30 or 30x20, etc.)
- test scenarios with IS pers SubFarm / LocalController
per node.
- also, with PTDummy we can test the influence of event_size and CPU_BurningTime on performanceQ2: by definition
Q3: Andrea, Serge, Sander, Haimo
Q4: yes, Q5: yes
Q6: can run shared. exclusive access needed only in case of problems
Q7: as many nodes as possible
Q8: no
4. Step 4: integration: ONLSW + L2 ROI Collection + Event Builder + EF (step 2+ step 3
together)
Doris + Sonja
description of partitions to run: (to be prepared)
estimated time for verification:
estimated time for sub-system tests:
• Test integrated functionality
• Take Measurements for state transitions for increasing number of elements
• Verify robustness with the help of operational monitoring while in running state
Note that the so-called standalone tests of both the LVL2 and EF software are in fact already binary
tests of the LVL2 and EF software respectively with the Online Software. Although some of the control
software has been customized specifically for use in the HLT (e.g. the Local Controller implementation
of the Run Control) the HLT supervision system as a whole relies heavily on the Online Software
infrastructure for process control, inter-process communication, monitoring, etc.
Component tests for the Online Software Information Service were planned to be performed at the
beginning of the tests in order to use the resulting information in the optimization of configuration
parameters for the subsequent integration tests. Tests for the Configuration Databases, Setup, and for
Web services were planned to be performed at convenient times, independently of the integration steps
described.

Giovanna coordinating the test
estimated time for the tests:
for some of our new components: 1) Access Manager (Marius): Given a large partition (might be purely dummy or contain real DF applications) evaluate the performance loss at setup and transitions introduced by switching on the access management. Some time should be allowed to try to optimize AM (cache lifetime) and Corba parameters. For using the AM we need 1 machine configured as a MYSQL server, containing the AM database. These tests should be performed towards the end of the testing period, if and when the rest of the system is fairly stable.
At every change of size of the system, a partition should be run and timed with the AM deactivated and then with the AM active. Time differences for booting and transitions shall be recorded. If feasible, the AM should be then always kept active. - To use the AM we need a mysql server and a users database. Marius will follow up with Gokhan that we have a machine installed for this purpose on lxshare. - John-Erik and Marius will provide instructions on how to activate/deactivate authorization via the AM. (1 Variable in the database, at Partition level). - Marius will execute the timing tests for this component. 2) DVS (Alina): Scalability tests. Some time should be dedicated to see the performance of DVS, when very large number of tests are launched. In general, DVS shall be used throughout the testing period, for testing and logs browsing, etc... 3) Setup(Andrei): Setup shall be used for all tests. This LST period shall definitely assess its functioning. Dedicated time should be scheduled to see how well we manage to recover when infrastructure applications are killed.
- No specific test, but assistance from Andrei if there are problems. - Andrei will check that the text_gui works from within setup. 4) New PMG (Marc): on dedicated release Dedicated time to start/stop/monitor large number of processes and measure performance. These tests will be made with dedicated test programs, not with the DAQ. When these tests are ongoing the system shall be locked, in order not to mix up old and new pmg agents. We would like to get 2 days for this (one between 21-26 of June and one towards the end of the LST period). The second day might be dropped if everything works fine during the first tests.Tests will first be done on building 32 testbed. Then need 1/2 day exclusive mode.
- tests will be first carried out on bdg 32. - If successful, 1 day of parasitic running on (part of) the cluster will be asked (beginning of July) to install the software needed and do preliminary tests, followed by half day of measurements (exclusive usage) - If the first tests will have been succesfull another timeslot towards the end will be requested to run some automated measurements (can be done over night). 4) New RC (Giovanna): on dedicated release Dedicated tests on large (dummy) partitions to verify the functioning of the new run control and supervision. If everything works fine the new RC could be used for real partitions as well. These tests will require the installation of a second release containing the apps linked against the new RC. Tests could start after June 26th. Tests will first be done on building 32 testbed. Then need 1/2 day exclusive mode. If tests are successful, new controller could be used from then on. (boot and shutdown are expected to be faster because of distributed dsa_supervisor.
- Tests will first be carried out in bdg 32. - If successful, during July we will run a few equivalent partitions with old and new Controller and check if the behavior is similar, performance wise. One day will be enough for this. During the night we might then be able to make comparative automated timing tests. - Another slot of automated tests will be asked towards the end of the period, if the first tests were successful.
- current RC:
- at every change of size, run a partition with Controllers and ExampleApplications only to test completely the run control chain. - if there will be spare time, applications and controllers shall be killed on purpose, randomly, to check that they are restarted/ignored as specified in the DB and that the system behaves as expected.
5) IGUI Mihai
Tests on large partitions on particular aspects of the scalability of the IGUI panels. Last year the IGUI has been used for configurations including up to 150 nodes. We will check the behaviour for larger configurations (for example 400 or 500 nodes), especially for PMG, Run Control, DataFlow and MRS panels.
- During setup time (at each relevant size change) the IGUI shall be tried out to check its scalability. - setup_daq shall always be started without GUI, then we will try out 2 different ways of running the IGUI: either started on a local machine outside the lxshare cluster (fast graphics, but potentially large latencies over the CERN network to send commands, etc...) or started on a dedicated machine within the lxshare cluster with a remote display (fast command distribution, but slow graphics response). - the general shifter in charge of setting up the system shall use the IGUI, assisted by Mihai, if/when needed.
Log Service: - it is requested that a partition stays up for sometime (30 minutes). - the log server will be started parasitically, but it might have an impact on the load in the mrs_server (keep an eye on CPU load!). - Log consumers will be requesting data and we will evaluate at which point log messages will start to be dropped. - this exercise should be repeated at each size change, if no evident problems have appeared. - Raul will contact Gokhan to tell him what is needed from an installation point of view (mysql and web servers). - These tests can be done with any partition. Raul will measure the behaviour of the LS.
------------
The developers will be running the specific tests. that's why the first week is not suited for the pmg. For what concerns the AM, I will run the tests myself, since John-Erik will be leaving for good at the beginning of June. He has started tests on medium scale already (bdg 32). In general people in Controls will participate to the tests also when running in integrated mode. We'll have to sort out the coverage of the full period.
Absences:
Alina: 09 June - 26 June Roul: 1.7 - 5.7 (possibly longer) and 18.7 - 29.7. Giovanna: 11.6 - 26.6, 16.7 - 24.7. Andrei: 2.07-25.07 Marc: 11.6 - 19.6, 11.7 - 17.7 (or 13.7 - 17.7) Mihai: 08.07 - 01.08.
Several people available for general shift for a few days, possible times are known
Sergei coordinating the tests
Here is the test plan for the Monitoring Working Group.
1. *what is the purpose of the tests, which aspect of the system is
investigated, what are the objectives (description of the test)?*
The main aim is to test scalability and performance of the IS, OH and Emon
components.
2. *why can these tests only be done on a very large scale, what are
the challenges and/or expected results?*
Each of those components should be able to serve a couple of thousand
clients, therefore in
order to verify their functioning in this conditions and measure their
performance one
should have a couple of hundred computers to run those clients.
3. *who will prepare the tests, who will participate in the test
preparation (be the contact person, participate in meetings), run
the tests and make the results available as part of the test report?*
The tests for the IS and OH will be prepared and done by Serguei Kolos.
Tests for Emon
will be done by Ingo Scholtes.
4. *will the tests have been tested and run on a medium scale on one
of the available farms before?*
Probably not on the medium scale farms, but we will make some standalone
tests in order to verify
the functionality of the components.
5. *can the tests be automated? Can they run autonomously, i.e. over
night or during parts of the week-end?*
Yes, all or at least most of the tests can run autonomously.
6. *do the tests require exclusive access to the farm or can they run
in 'shared' mode?*
All the tests will require exclusive access to the farm.
7. *how many nodes and how much testing time do they require a) in
shared mode b) in exclusive mode?*
The number of nodes is not a crucial issue since we can vary a number of
clients per node. Of course a high number of machines is preferable, however
I would say that any number of computers between 300 and 700 is suitable.
What is really important is that these computers must be used in exclusive
mode for those tests.
8. *are there any specific requirements on system parameters or any
constraints?*
Nothing special apart from the general LST requirements.
requested testing time: 1 day share mode, 3 x 1 night for automatic tests exclusive mode; on 400-500 nodes => around LST phase 4
Absence of Sergei: 5-18th of June. Ingo will come for 4-5 days starting from 21st of June
Igor coordinating the tests
Need an IT oracle server exclusively and testing period will depend on its availability; Envisaged: LST phase 2-3
setting up during shared mode,
exclusive automatic tests and can run over night (to be verified)
Absence: Igor: from 11th of July onwards.
Nuno coordinating the tests
The information for my tests are:
1) PURPOSE: The purpose is to check the performance of the new COOL based CDI. In this checks it is intended to see if the new implementation cope with the online community performance requirements. Some of the tests include subscribing data to the IS in regular (measured) intervals of time, checking the limit with which the CDI can cope, using the CDI together with multiple IS servers and using CDI with multiple clients publishing at the same time different (or the same) objects.
2) why can these tests only be done on a very large scale, what are the challenges and/or expected results?The tests can only be meaningful when made in a environment the most similar possible with the real usage. In practice the CDI will be used by many clients, many ISServers which will most likely publish data to be stored at a very high rate. Although it is possible to make this tests in a single or just a few machines, the meaning will be completely different as we will not have the idea of the effects of parallel data publishing.
3) who will prepare the tests, who will participate in the test preparation (be the contact person, participate in meetings), run the tests and make the results available as part of the test report?
All these tasks will be my responsibility. However, during this week it will not be possible to participate in the meetings as I am away.
4 ) will the tests have been tested and run on a medium scale on one of the available farms before?
Not these tests. The CDI was already tested before, but with different goals (more in the sense to check if the underlying Conditions Database was per formant enough). The current tests are intended to test the CDI implementation itself and check how much can be improved in the CDI side. Since the COOL API is a project from CERN IT, these tests will also allow to check which improvements the ATLAS experiment can ask to the COOL development team.
5) can the tests be automated? Can they run autonomously, i.e. over night or during parts of the week-end?
In principle yes. The tests are quite simple, but if something goes wrong it is not clear if the environment will recover to start another set of tests. The best would be to test with someone (me) taking care of them. Anyway the tests can be changed to handle any errors that might occur. The problem is that will require time that I'm not sure to have.
6) do the tests require exclusive access to the farm or can they run in 'shared' mode?
They can be run in shared mode as far as the other processes do not take too much resources or else the time measures will be biased.
7 ) how many nodes and how much testing time do they require a) in shared mode b) in exclusive mode?
In both the tests would not require more than one/two days. One day should be enough. There are not many tests and in anyway the CDI will be implicitly tested in other packages that use it as a mandatory component (eg. the setup_daq application).
8) are there any specific requirements on system parameters or any constraints?
No other than have access to an Oracle server preferably with exclusive access.
Haimo coordinating the tests
here is the combined list of proposed tests from EF and LVL2.
For each of the tests, I added the 8 questions from the LST page
"HowTo participate in the test" with the answers from the HLT group.
Q1. what is the purpose of the tests, which aspect of the system is
investigated, what are the objectives (description of the test)?
Q2. why can these tests only be done on a very large scale,
what are the challenges and/or expected results?
Q3. who will prepare the tests, who will participate in the test preparation
(be the contact person, participate in meetings), run the tests and
make the results available as part of the test report?
Q4. will the tests have been tested and run on a medium scale on one of the
available farms before?
Q5. can the tests be automated? Can they run autonomously,
i.e. over night or during parts of the week-end?
Q6. do the tests require exclusive access to the farm or can they run in
'shared' mode?
Q7. how many nodes and how much testing time do they require
a) in shared mode b) in exclusive mode?
Q8. are there any specific requirements on system parameters or any constraints?
I've grouped the tests by whether they need Athena, and combined those that are common
for LVL2 and EF. It's a bit long due to those 8 questions, but I think
they give us a nice view of what we want to do.
- Haimo
Proposed HLT test plan for 2005 Large Scale Tests
=================================================
Name abbreviations:
AdA - Andre dos Anjos
AB - Andre Bogaerts
HG - Hegoi Garitaonandia
SS - Serge Sushkov
HZ - Haimo Zobernig
AN - Andrea Negri
SK - Sander Klous
Tests which don't depend on HLT selection algorithms:
-----------------------------------------------------
Test 1) SW distribution with BitTorrent
Haimo coordinating the tests test distributing a "shrink-wrapped" sw distribution containing the tdaq-01-01-00, offline 10.0.2 and hlt-02-00-00 releases, combined into a single, pre-tested filesystem. This would be a compressed .iso file of ca. 1.7 GB ( 5GB expanded ). Q1: The method of distributing this to N nodes which we wish to test is by using the peer-to-peer protocol BitTorrent. We have tested it with up to 50 nodes on Fast Ethernet. Maximum time observed was 30 mins to distribute 50*1.7 GB = 85 GB on 50 nodes. (see https://uimon.cern.ch/twiki/bin/view/Atlas/HltSoftwareDownload ) Q2: We would like to run this test in all the different sizes of the LST to get measured timing on its scaling behaviour. Expected scaling should be logarithmic with number of nodes, or better. But it will depend on other concurrent network activity. Q3: HZ AdA HG Q4: yes, already done on up to 50 machines Q5: yes, test can be run in automated way, eg by cron job Q6: for initial verification shared mode is ok, for scaling measurement exclusive access is preferred (largest configuration may need 1-2 hrs if log scaling applies, see Q2) Q7: the maximum available in each phase of LST (see Q2) Testing time initially a few hours if problems appear. BT itself is very well tested by the worldwide Internet community... Q8: requirements: a) a local disk area with at least 5 GB of disk space on every node b) ability to mount an .iso file as a read-only file system c) BitTorrent version 3.4.2 or higher. If tests are successfull we may want to use the new "trackerless" version 4.1.1 of BitTorrent, which supports many thousands of simultaneous downloaders of the same file. This would be interesting at least for 500 or more nodes in the LST. Test 2) verify this file system with known-to-work tdaq-only partition Q1, Q2: make sure larger partitions work, as tdaq-01-01-00 may behave differently from tdaq-01-02-00 Q3: HZ AdA AB Q4: yes Q5: yes Q6: can run shared Q7: some large partition should be tried, but not necessarily in all LST sizes Q8: no Test 3) run w/ preloaded events, but dummy algorithms Q1, Q2: Learn behaviour of large partitions with preloaded events. Run a TDAQ partition w/ dummy algorithms, but with events preloaded in ROS (preferred, w/ ROSE as backup alternative) This test is also a prerequisite for test 6) Q3: HZ AdA AB Q4: yes, done with small partitions in lab32 Q5: yes, Q6: shared OK, fraction of cluster to be determined Q7: same as Test 2) Q8: no Tests with HLT sw (thus requiring tdaq-01-01-00, Offline 10.0.2, HLT-02-00-00): ------------------------------------------------------------------------------- Test 4) HelloWorld and Level1 decoding test Q1: run algorithms 'HelloWorld' and 'HelloWorldLVL1' Both algorithms test much of the Athena infrastructure as used in HLT. Memory consumption, disk access patterns and shared library use will be studied. HelloWorld applies equally well for LVL2 and EF, while HelloWorldLVL1 decodes the Level 1 result and is known to be working - even in multi-threaded mode - and constitutes a LVL2-specific test Q2: verify use of Athena in LST for the first time. verify the LVL1 decoding part of the LVL2 trigger in multithreaded mode on large partitions. Q3: HZ, AdA, AB, SS, HG, AN Q4: yes Q5: yes Q6: shared OK (part of cluster, not sharing same nodes) Q7: 50 to 100% of cluster (100% for a final test). Running time 5-30 minutes per test Q8: no Tests which depend on availability of working algorithms: --------------------------------------------------------- These tests must use tdaq-01-01-00 as Athena doesn't yet work with the new tdaq release; all required sw will be distributed via the .iso file downloaded in Test 1 - we assume this will work as tested in lab32. The algorithms to be tested here may not be available during the first, smaller phases of the LST. They will have a chance of getting distributed every time Test 1 is run. Test 5) test HLT configure behaviour Q1: if any algorithm is available, that has been demonstrated to at least survive the 'configure' transition, we wish to test this transition in all the LST phases. This applies to LVL2 as well as EF. Q2: understand scaling problems with access to databases, loading shared libraries etc. Needs cooperation with DB management group due to large bursty load generated by the many DB clients. Q3: HZ, AdA, AB, SS, HG, AN Q4: yes Q5: probably needs manual running to observe behaviour in real time Q6: shared mode OK Q7: good fraction of cluster, maybe ~50%, probably not 100% (until everything is in good shape and under control) Q8: DB access may pose restrictions, but not yet known in detail Running time could be substantial if test is working at all, due to many parameters to be studied (many short runs). Details still need working out. Test 6) test HLT run phase Q1: if any algorithm is available that is known to run on smaller testbeds in LVL2 and/or EF, we wish to test it also with all LST sizes, (using realistic, non-dummy events). Might be done separately for LVL2 and EF i.e. vertical slice probably only in the most optimistic of cases. Q2: study runtime behaviour of algorithms, look out for unexpected/forbidden database accesses during event processing. study resource consumption such as memory foot print (watch for leaks), network load, cpu usage etc. with many nodes.. Q3: HZ, AdA, AB, SS, HG, AN Q4: yes Q5: yes, but will also need some handholding... Q6: shared mode OK Q7: as Test 5), but running time may be substantial if all works in short runs (eg. long run on many nodes is a good way to find memory leaks and rare but serious problems) Q8: as Test 5) Tests specific to EF requiring no Athena algorithms: ----------------------------------------------------
Andrea and Serge coordinating the tests These tests should preferrably be done with the tdaq-01-02-00 release to benefit from recent improvements there. They can be scheduled independently of the HLT tests requiring Athena.
note: the description of these tests has been moved to the section on sub-system tests. Preparation tasks for the tests Software installation and administration
Gokhan and Matei responsible
Database generation tool
Gokhan responsible
Tools
All to contribute
Preparation and documentation of testing tools is on-going. The documentation of those tools will be published on the LST web page, a number of documented items can already be found there. A twiki page has been created to give easy access for making contributions, corrections and discussion. Stable items will be moved into the main LST page.Areas concerned are: